2011
Description
POWERFIT is a short IDL function designed to fit for the parameters of a power-law plus constant model using full covariance information, with or without conditioning the covariance matrix as described in Matthews & Newman 2011. The analysis in Matthews & Newman 2011 showed that ridge regression conditioning yields great improvement in the worst-case errors, but smaller improvements in more typical cases.
Given arrays containing the independent variable values x, the dependent variable values y, and the covariance matrix of the y values, C, POWERFIT determines the best-fit parameters for a function of the form y = axb + c via χ2 minimization. It outputs the best-fit parameter values in the form of a three-element array, i.e. [a,b,c]. For a fixed exponent, b, the best-fit values of a and c are calculated analytically using standard linear regression formulae. To fit for all three parameters simultaneously, POWERFIT uses the AMOEBA function (distributed with IDL, and based on the routine amoeba described in Numerical Recipes in C) to search for the exponent value that minimizes the χ2 of the fit.
POWERFIT optionally allows the user to fix either the exponent value, b, the constant, c, or both, at specified values when calculating the fit. It is also possible to condition the covariance matrix using either of the methods described in Matthews & Newman 2011. For ridge regression conditioning, the user must provide a value for ƒ (where ƒ is the fraction of the median of the diagonal elements of the covariance matrix to add to the diagonal elements before inverting). For SVD conditioning, the required input is the singular value threshold; any singular values below that threshold, as well as their inverses, are set equal to zero before calculating the inverse of the covariance matrix. The code is suitable for any application where a power law or power law plus constant model is fit to data with a known covariance matrix.
In several very different cases, we found that ƒ≈3% ridge regression conditioning was optimal for minimizing worst case errors, where ƒ is the fraction of the median of the diagonal elements of the covariance matrix to add to the diagonal elements before inverting. Although we recommend performing a risk minimization as described in Matthews & Newman 2011, this is likely a good initial guess at an optimized conditioning level.
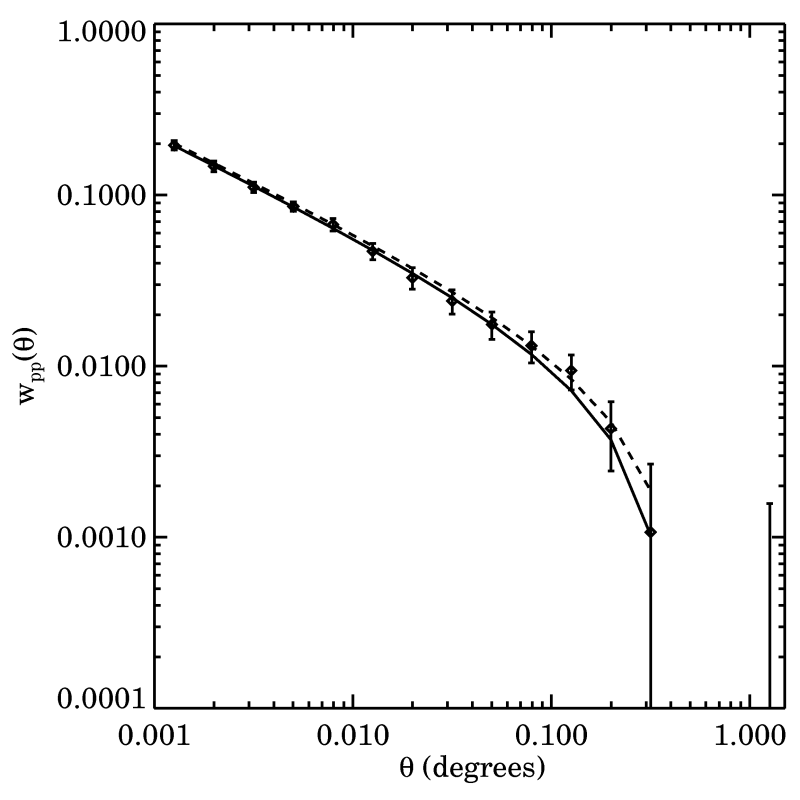 Figure: An example of fitting a power law plus constant model to an angular autocorrelation measurement from DEEP2 Millennium mock catalogs produced by Darren Croton. The solid line is a fit assuming no covariance between angular bins, while the dashed line is a fit calculated with POWERFIT using the full covariance matrix with ƒ = 3.5% ridge regression conditioning.
Figure: An example of fitting a power law plus constant model to an angular autocorrelation measurement from DEEP2 Millennium mock catalogs produced by Darren Croton. The solid line is a fit assuming no covariance between angular bins, while the dashed line is a fit calculated with POWERFIT using the full covariance matrix with ƒ = 3.5% ridge regression conditioning.